Статьи о Marquee
Тестирование поисковых машин по индексации бегущей строки
Сентябрь 2013 г.
Для большинства издателей сайтов имеет значение повышение посещаемости своего сайта, проще говоря "раскрутка". Рейтинг сайта повышается если заходы осуществляются из избранных закладок, и совсем шикарно если сайт установлен как стартовая страница, но такие заходы имеют только мощные порталы, с востребованными сервисами: поисковики, социальные сети или серьёзные интернет-магазины или порталы с любимыми онлайн играми. На сайтах посвящённым вопросам SEO (поисковой оптимизации сайтов) указывают, что наибольшую ценность для продвижения сайта имеет цитируемость: количество прямых ссылок на страницы сайта с других ресурсов. Вторым по значению, специалисты SEO считают, индексацию в поисковых системах и попадание ссылки на сайт в десятку первых (в топ) предоставляемых тем или иным поисковиком по определённой теме запроса. Как известно поисковые системы, а вернее сказать специальные программы-роботы, сканируют доменные зоны отслеживая, появления новых сайтов, новых страниц, баз данных, изменений или удаление файлов на сайтах. Результатом сканирования записывается в базу данных того или иного поискового ресурса. Копирование сайта в такую базу данных, собственно и является индексацией. Сайт копируется только в том случае, если его содержание и структура отвечают политикам конкретного поисковика. Эти политики (требования) указываются в правилах поисковой системы, и доступны для ознакомления для всех желающих. А вот определение релевантности, т.е. соответствие запросу при вызове из базы данных, это уже тайна за семью печатями. Впрочем известно, что релевантность вычисляется по так называемым ключевым словам и фразам. Но определение оптимальной плотности ключевых слов на объем текста у поисковых систем отличается, что хорошо для одного поисковика, может являться плохим показателем для другого. Недостаточность ключевых слов понижает релевантность, и ссылка на страницу не попадает в топ, а переизбыток ключей, может быть воспринят, как поисковый спам, и страница вообще не записывается в базу данных, а сайт может оказаться под баном поисковой системы.
Но, это несколько упрощённое описание определения релевантности. Её вычисление зависит от многих условий: и плотность ключевых слов, и цитируемость страницы (учитывается кстати и цитируемость сайта на котором обнаружена ссылка), и показатель частоты и продолжительности просмотров страницы и многое, многое другое. И всё таки вернёмся к ключевым словам. Релевантность слова зависит не только, от количества его повторений в тексте, но и от того в каких тегах это слово используется, так например известно, что в тегах заголовков <H> коэффициент слова выше чем, в теге параграфа <P>, но его коэффициент повышается если оно есть и в заголовке и в параграфе, ещё выше его рейтинг если слово выделено <EM> или <Strong> (наклонным или жирным шрифтом), и наивысший коэффициент, если слово используется и в заголовке странице (титле), <H>, и в тексте.
Автора этой статьи, одолело любопытство, а как поисковые системы смотрят на тексты в самом скандальном теге всех времён и народов <Marquee>. С одной стороны это тэг создающий динамический эффект скроллирования контента, более известного, как бегущая строка, не включён в спецификацию HTML4, т.е. невалиден, а с другой стороны, это блоковый управляющий контейнер, такой же, как <DIV>, <H>, <SPAN>, <P> и др. Найти информацию о том, как та или иная поисковая система реагирует на текст в <Marquee> автору не удалось, и он решил провести собственный эксперимент. Для начала изрядно потерзал, популярные поисковые порталы, нашёл два слова, которые поисковики не смогли найти ни по отдельности, а тем более в паре (слова естественно выдуманные, некий странный зверёк, или чёрт его знает, что...). Следующий шаг: эти слова были записаны только в одном документе в тег бегущей строки (статья Текст в Marquee), вот скриншот этого примера:

В наставлениях для вебмастеров, часто можно встретить рекомендацию: тестировать сайты текстовыми браузерами, так как поисковые программы (пауки, боты, краулеры, роботы, сканеры) видят содержимое страницы, аналогично этим самым текстовым браузерам (Marquee в текстовых браузерах). Самый известный и рекомендуемый текстовый браузер: Lynx (лат. Рысь). Ну так и посмотрим, рысьими глазами:
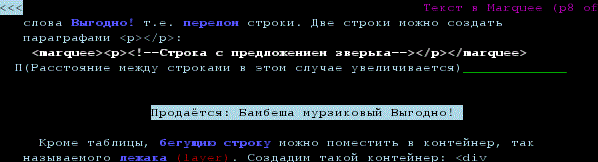
Lynx без каких либо дополнительных настроек увидел контрольные слова, значит текст помещённый в <marquee> отображается в текстовых браузерах. Но всё таки поисковые боты, видят страницы иначе, они видят настройки веб сервера, метатеги в голове страницы <head>, теги в документе, наверное это похоже на просмотр исходного текста веб страницы. Как видим интересующая нас контрольная пара слов, расположена в тэге <span> вставленный в бегущую строку, которая в свою очередь установлена в табличную ячейку:

Итак, сайт А-СТО размещён на сервере бесплатного хостинга Народ, который был создан в 2000 г. Яндексом. В 2013 году Яндекс передал народные сайты популярному бесплатному хостеру uCoz. Сайты на бесплатных хостах, да ещё и в доменах третьего уровня, как на Народе, или uCoz'e индексируются гораздо хуже, чем сайты размещённые на платных хостах. Обратим внимание, что на народных сайтах, размещались только статические страницы, для современного сайта, это бесспорно недостаток, (при переходе на новую платформу uCoz'a в народных сайтах вполне можно создавать динамические документы), но с другой стороны, статические страницы сайта, в отличии от динамических, проще для сканирования индексирующими роботами. Тестирование, автор начал именно с Яндекса:
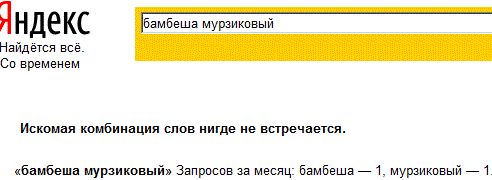
Результат отрицательный, точно также отвечал Яндекс, до того как, была загружена страница с указанным примером. Повторяем тот же запрос, в недавно запущенном поисковике, международном варианте Яндекса, Yandex.com, (на момент тестирования это ещё альфа-версия):
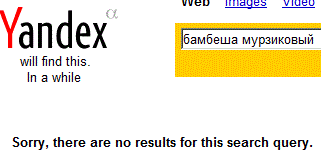
Тот же, отрицательный ответ, только на английском языке. Возможно страница вообще не проиндексирована и её нет в базе Яндекса. Проверяем. Делаем запрос, указав заголовок статьи, т.е. <title> документа, ведь титл-заголовок страницы, это первое, что индексируют поисковики:
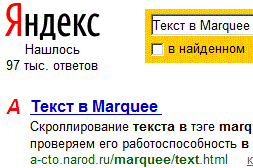
Убеждаемся, что тестируемый документ находится в базе данных Яндекса, т.е. проиндексирован. Сделаем ещё одну проверку: локальный поиск по сайту предоставляемый Яндексом, в этом случае поиск происходит не по базе данных, а непосредственно по страницам сайта:

Но, ответ, вновь отрицательный. Продолжим любопытствовать: а как ответит поисковая система на тот же самый запрос, во втором по популярности поисковике России: Rambler:

Рамблер так же, не смог отыскать, контрольные слова, правда в отличии от Яндекса, ответ не является категорическим отказом. Рамблер предлагает варианты, например Тому против Люксембурга, он предлагал их, когда автор подбирал слова для эксперимента. Но, возможно искомая страница не проиндексирована Рамблером. Повторяем проверку по заголовку (титлу) документа:

Страница выведена в первой строке, значит документ записан в базу данных, проиндексирован. Что ж, продолжаем исследование, запрашиваем и смотрим копию страницы из базы данных Рамблера:

В сохранённой копии, проверочные слова отсутствуют, вместо них пустышка. Повторим, те же самое в Яндексе, т.е. смотрим сохраненную копию в индексной базе Яндекса:

В отличии от Rambler'a, в яндексной копии искомый фрагмент присутствует. Получается Рамблер фильтрует тег marquee при копировании (при индексации), а Яндекс копирует marquee, но фильтрует контент в тэге, при выдаче. Впрочем эксперимент, проводился в 2010 году до того, как Рамблер прекратил использовать, собственную поисковую машину в 2012 году, и полностью перешёл на технологию Яндекса. БРамблер как поисковый портал сохранился, но поиск осуществляется по базе Яндекса.
Итак: текстовое содержание (контент) не индексируются в поисковиках Яндекс и Рамблер. Но, это далеко не единственные поисковики которыми пользуются в Рунете. Проверим? как ответит на тот же каверзный вопрос, самый популярный в мире поисковик Google:
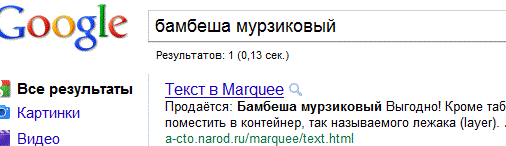
Гугл без проблем, нашёл контрольные слова. Безусловно Google это мощная мультипоисковая система, имеет свой каталог, свою базу сайтов и плюс заглядывает в базы других поисковиков. Google на шаг, а то на два шага опережает, другие системы, и качеством поиска и предложением множества дополнительных сервисов, не говоря уже о рекламных программах AdWords и AdSence, которые используются половиной веб-сайтов Интернета. Если погуглить то, мы обнаружим массу поисковых систем, которые осуществляют поиск по технологии Google. Всё очень быстро меняется. Актуальность статьи понижается с каждым кварталом. Многие примеры могут совершенно не соответствовать реальной ситуации в секторе поисковиков. Напомню, что тест проводился в 2010 году. Возможно через года три, четыре, никого не заинтересует вопрос: индексация текста бегущей строки. Но в 2010, мы видим, что она индексируется в некоторых системах, вот только, релевантность текста помещённого в контейнер <marquee></marquee> весьма низкая, так как в списке приоритетных тэгов он отсутствует, по причине невалидности, (смотри статью: Невалидность Marquee т.е. этого тэга, формально в веб-документах, вообще не должно быть. Современные тенденции в SEO для Рунета упрощаются, в плане ориентации на поисковые машины, задача сводиться к оптимизации сайта под Google и Яндекс. Но, так как Гугл, и некоторые другие поисковики всё таки, индексируют текстовое содержание бегущей строки, то надо учитывать, что запись ключевых слов в контейнер marqueе, всё таки, повышает их плотность в веб документе.
Если, моему уважаемому читателю любопытно, а как бегущую строку индексируют другие поисковые системы, то давайте продолжим поиск очень странного зверька.
Поисковых систем очень много и проверить их все, задача нереальная, поэтому автор протестировал несколько, на его взгляд заслуживающих внимание поисковиков. Но автор вынужден повторится, что статья была написана в 2010 году, и ситуация с интернет поисковиками изменяется каждые полгода. Одни поисковики прекращают своё существование, появляются новые, а некоторые системы меняют ориентацию поиска. Если Вы не устали, то продолжим. Помимо, поисковиков, которые сканируют доменные узлы, и создают свои базы данных, существуют метапоисковые машины, которые осуществляют поиск по базам основных поисковиков, при условии: что базы открыты для них. Например базы Яндекса закрыты для метапоиска, частично закрыты в случае Google. Самая известная метапоисковая система это конечно Mamma.com, рекламный слоган этой машины The Mother of All Search Engines (Мать всех поисковых машин):

Вот результат от Маммы однозначен, где-то в Интернете, в базе или базах данных есть копия страницы А-СТО, с упоминанием странного существа в бегущей строке. Жаль, но Мамма, не указывает где она отыскала ответ, да и заявление о всех поисковых машинах, несколько преувеличено, Mamma.com не работает с базами российских поисковиков (впрочем Мамма тоже изменилась, со времени тестирования), да Мама уже не та... Обратимся к другому поисковику, Yippy.com (прекратил существование.
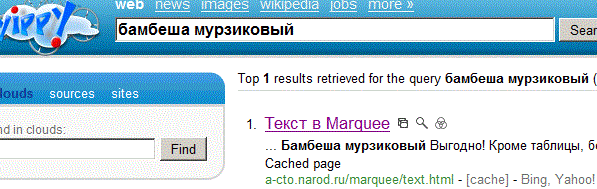
Yippy чётко указал два серьёзных ресурса: относительно новая поисковая система Bing.com от MicroSoft и суперкаталог Yahoo!. Эти порталы хорошо известны российским пользователям Всемирной Паутины. Автор? почти наверняка уверен, что и Mamma, нашла именно эти базы. И в русском сегменте работают аналогичные метапоисковики, правда без опции анонимайзера, например Metabot:
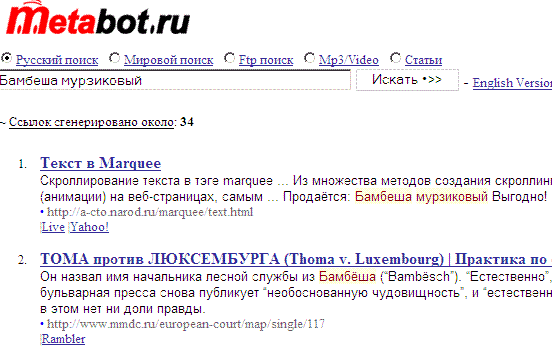
Ответ Метабота, показал, что Rambler свою базу держит открытой (та же Тома против Люксембурга), но вот однозначно сказать, для всех ли он открыт или выборочно, почему Yippy не показал его базу. Может Рамблер закрыл для этого метапоисковика свой индекс, или Yippy не пожелал заглядывать в Рамблер. Ссылка же на Live.com не должна смущать, это недолго просуществовавший (2008 год) ресурс, который сменил в 2009 году на Bing.com, просто администрация Metabota, ещё не успела изменить адрес, впрочем переход по ссылке Live приведёт к редиректу на Bing, который как мы видим в режиме бета-версии:
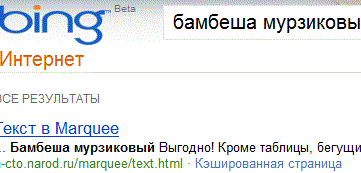
Действительно Bing, прекрасно проиндексировал необходимый нам пример, однако учитываем, что MicroSoft всегда придерживается технологии метапоиска в своих системах. Продолжаем путешествие по интернет поисковикам. Положительный результат на запрос, автор получил и от суперкаталога Yahoo!:
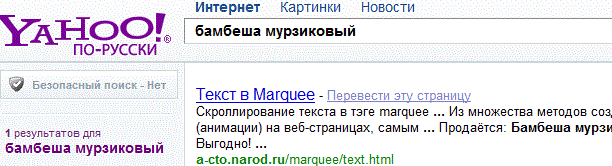
Но с Yahoo!, есть один момент на который надо обратить внимание. Запрос был выполнен по русскому сервису: ru.yahoo.com, потому, что основной ресурс Yahoo.com не найдёт, такой простенький русскоязычный сайт, как А-СТО Дайджест. Подобную ситуацию наблюдаем и с Ask.com, который выдал отрицательный результат:
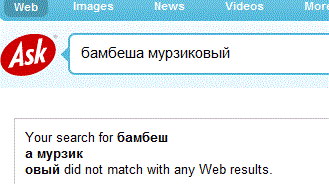
Но, при переходе на русский сервис AskJeevs по адресу ru.ask.com, искомая комбинация слов была обнаружена. AskJeevs имеет весьма своеобразную концепцию поиска, и у пользователей Рунета десятого года, AskJeevs третий, по популярности международный поисковик после Гугла и Яху.
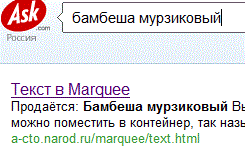
Продолжим охоту за зверьком, и зайдём на сайт Alexa.com основного рейтингующего ресурса в Интернете, при заходе на главную страницу можно посмотреть топ десяти самых популярных веб-ресурсов, в основном это поисковики и социальные сети (блоги), при желании можно посмотреть и топ 500, запросить, а кто там на тысяча сто тридцать восьмом или миллион двести десятом месте:
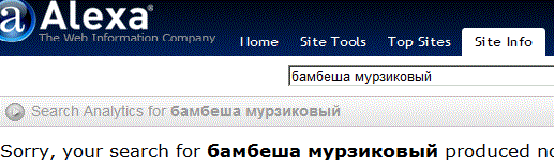
Контрольные слова, Алекса не нашёл, и не найдёт на сайте А-СТО. Дело в том, что этот поисковик принадлежащий интернет магазину №1 в мире Amazon, вообще не индексирует документы в поддоменах (доменах третьего уровня), т.е. ресурс Narod.Ru, Alexa знает, но сайты на Народе не индексирует. Кстати рейтингует Алекса своеобразно. Его программы учитывают только заходы на сайты из Windows осей, и только браузерами с тулбаром (toolbar) от Alexa, т.е. заходы из Linux, Solaris, xBSD, AIX и др. в расчёт не принимаются, но именно этот принцип оказался самый удобным и точным, для определения рейтинга веб-ресурса. Однако скриншот с отрицательным результатом это уже история, Алёха более не ищет, а только рейтингует. В 2010-ом автор обращался с надоедливым вопросом и к легенде поиска в Интернете, к AltaVista:
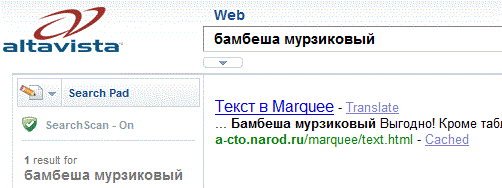
Легенда ответила положительно, она прекрасно нашла проверочные слова в скроллинге. Кстати именно AltaVista предложила веб-мастерам использовать метатеги kеywords и description для улучшения индексации документов, а теперь ключевые слова называют проклятием Интернета, многие поисковики так и не приняли для чтения эти метатеги. Но..., легенды уходят, и AltaVista, приобретённая Yahoo! прекратила своё существование. Одни уходят, другие приходят, так в сети появился стартап, новый поисковик Alhea, совместный проект Google и Yahoo! на базе поисковой системы InfoSpace, поэтому не приходиться удивляться, что Алхиа нашла искомого зверька без затруднений:

Ещё одна легенда веб-поиска: Gigablast самая зелёная поисковая система, вот так, ни больше, и ни меньше:

Gigablast не обнаружил удивительного зверька, впрочем А-СТО вообще отсутствует в индексе, по титлу необходимая страница тоже не обнаружена, возможно А-СТО недостаточно чистый сайт и не отвечает зелёным правилам Gigablast. Возможен ли индекс в marquee Гигабластом, автор затрудняется дать ответ. Вполне возможно Gigablast всё таки проиндексирует А-СТО, вот тогда можно будет проверить, как он индексирует текст в теге автоматического скроллинга. Вот ведь проиндексировал же А-СТО Lycos.com, кстати, чем крайне удивил автора:

Это не просто легенда, это легендища. В девяностые годы прошлого века, когда в сети ещё не было ни Яндекса, ни Rambler, ни Google, ни Yahoo!, немногочисленные русские пользователи Интернета искали в сети с помощью AltaVista, Lycos, Tachoma, Exсite. Существовал и успешно действовал ресурс Lycos.Ru. Закрытие русского Ликоса для многих стало неприятным сюрпризом.
А вот кстати, российский внешний подражатель Google, с говорящим названием домена: Поиск.Ru, что ж, попросим его поискать зверька:
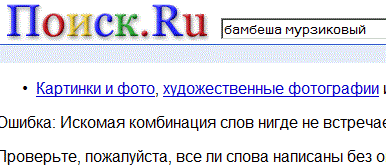
Несмотря на откровенное заимствование цветов Гугла, Поиск.Ru ничего не нашёл, и это неудивительно, потому, что Поиск.Ру, система поиска использует технологию Яндекса, а он как мы уже убедились, не индексирует бегущую строку. Хотя, некоторые системы использующие Яндекс технологию, умудряются таки, поймать загадочного зверька. Перейдём к Webalta, посмотрим, как она справится с вопросом:

Ответ Webalta положительный. Вебальта вполне самостоятельная система, и несмотря на жёсткую конкуренцию в сегменте поиска, это система продолжает действовать. Автор это к тому, что сеть знает немало поисковых стартапов, которые свернулись ещё в альфа-версии. Взять хотя бы, GoGo.Ру, проект от главного почтового портала Mail.RU. Несмотря широкую рекламу, и огромную сумму капиталовложений (почти 1 миллиард долларов), ГоГо, был закрыт, просуществовав всего пару лет. Единственно, чем запомнился этот ресурс, так это четырьмя глазами, которые забавно двигались следя за перемещением мышки (пользователи Gnome, хорошо знают эту прикольную прогу с глазками), ну не поисковик был, а игрушка.

Проект GoGo канул в историю, а вот сам Mail.Ru продолжает весьма, успешно развиваться. А, вот с контрольным запросом в сервисе поиска почтовика, получился любопытный казус. За время подготовки статьи автор получил в течении недели два разных ответа:

Не найдено ни одного документа по Вашему запросу, сказано как отрезано, но прошла всего одна неделя и...
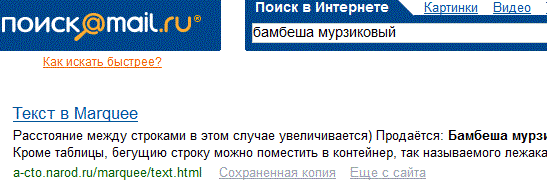
...и невиданный зверёк нашёлся. Конечно любой читатель может сказать, что графический файл, тем более с текстовым содержанием, легко редактируется. Ну уж хотите верьте, хотите нет, но это реальные скриншоты, и автор хотел бы, обратить внимание, что первоначально поисковый сервис Mail.Ru базировался на технологии Rambler, потом использовался Яндекс, это было очень заметно когда Mail.Ru показывал favicon (иконки) сайтов на которые выдавались ссылки, такая фишка с иконками, в момент тестирования, была только у Яндекса. И пока Mail.Ru дружил с Rambler и Яндекс, результаты поиска по зверьку были отрицательны. Но в конце 2010 года, для поиска стали использовать другую технологию (какую именно автор не знает), фавиконки исчезли, а зверушка... нашлась. Для такого проекта как А-СТО, вполне обычное явление, то попадать в индексы, то выпадать из индексов, т.е. скриншоты с ответами Mail.Ru через некоторое время вполне вероятно, можно будет поменять местами (ну не хотелось бы конечно), но всё очень быстро меняется.
Старейший, первейший поисковик Рунета: Aport.Ru. Результат запроса как видно на скриншоте, отрицательный, и всё закономерно, A-CTO отсутствует в индексе Aport:
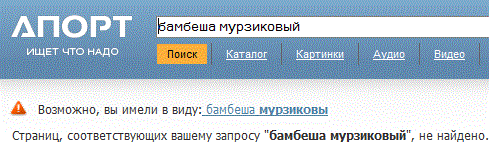
Но, дело в том, что автор сначала все эти проверки поисковиков на индексацию marquee, делал из любопытства для себя, и не помышлял о написании статьи. Поверьте на слово, Aport прекрасно находил контрольные слова. К сожалению, тогда, автор не догадался сделать скриншот. Aport за это время успел сменить дизайн своих страниц, и уже этот скриншот история. В те времена когда Апорт находил зверька, он выглядел вот так:
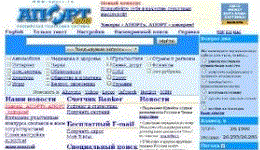
Апорт окончательно утратил свою популярность, и превратился в систему поиска только, товаров и услуг, кстати как и Рамблер, Апорт перешёл на технологию Яндекса, вот так уходят легенды.
И если Апорт это первая русская поисковая машина, всё таки сохранился пусть и в сильно изменённом виде, то один из первых краулеров, Интернета, поисковая система с громким названием AllTheWeb, совсем недавно как и AltaVista, прекратила свое существование, как говорится "канула в Лету"

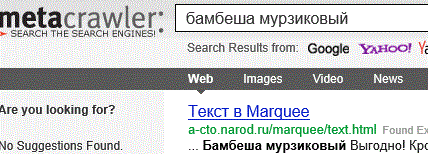
Но, во Всемирной Паутине продолжают действовать несколько классических поисковиков, действуют и кстати прекрасно вылавливают замысловатую пару слов написанную кириллицей в бегущей строке на странице примитивного сайта А-СТО Дайджест. Вот два примера, первый это MetaCrawler:
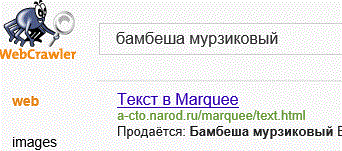
Второй, почти брат близнец Метакраулера, паучок WebCrawler:
Автор не мог обойти внимание ещё одну упомянутую выше, легенду поиска EXCITE. В современных рейтингах посещаемости её трудно отыскать. А вот в первые годы развития Web, этот поисковик занимал первое место, правда пользователей в сети насчитывалось чуть более одного миллиона человек. Именно в Excite, в 1999 году обратились два студента с предложением нового алгоритма индексации и поиска. Этим студентам было отказано. И они взяли да и создали Google. Эта история признана самой грандиозной ошибкой в сфере IT коммерции:
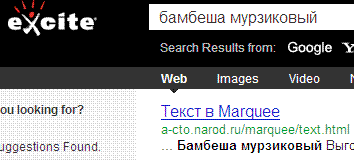
ВебКраулер, МетаКраулер, Excite это добротная, проверенная временем классика, которую теснят более новые поисковики, такие как Горячий Робот HotBot, разработчики этой системы первыми предложили пользователям возможность изменять шкурку, внешний вид страницы поисковика, сейчас это вполне обычная практика, но в свое время все эти хамелеонства, наделали много шума и соответственно привлекли к себе интерес:
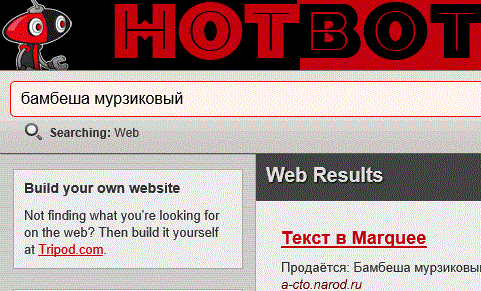
Для привлекательности своих ресурсов разработчики используют весьма забавные названия. Например Yahoo, слово выдуманное ирландским писателем сатириком Джонатаном Свифтом, которым он в Путешествии Гулливера, назвал человекоподобных существ в стране говорящих лошадей, и слово это означает, мерзкий, гадкий. Или вот поисковик который с некоторой натяжкой можно перевести как собачья куча DogPile:
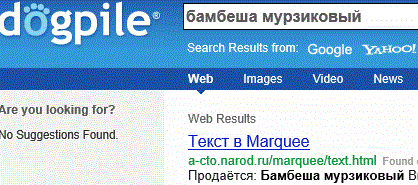
Эта куча по смыслу ближе к русскому выражению, где собака порылась. Ну, всё-таки некая ассоциация поиска присутствует. Но, как литературно перевести на русский язык DuckDuckGo?:

Впрочем, не смотря на столь забавные названия, это очень серьёзные и качественные поисковики, особо цениться у знатоков поиска DuckDuckGo, который осуществляет поиск через зашифрованный канал, обеспечивающий реальную анонимность в сравнении с Yippy и ищет информации по принципу как есть, в отличии от Яндекса и Google, которые надувают так называемый "пузырь" в соответствии с предыдущими запросами пользователя. Яндекс даже честно уведомляет, что при выдаче, учтены предпочтения пользователя. Это на самом деле, действительно очень удобно, но согласитесь, удобно, но, не всегда, вот для таких случаев, DuckDuckGo лучший вариант.
В списках поисковиков существует раздел национальных поисковиковых машин, практически в каждой стране есть такая система и не одна. Например автору очень понравилась Казахстанская поисковая система Kaz.kz:

А, вот старейший и популярный поисковик Украины META экспериментальные слова не обнаружил, и автор к сожалению не может сказать, индексирует или нет, бегущую строку МЕТА, так как А-СТО нет в индексе, и это наверно связано, с локальностью системы:

Поиск осуществляется только по украинским ресурсам, так, что локальность поиска, это ещё одна причина неиндексации веб-документа. Кстати говоря, существует категория специализированных поисковых систем, которые ищут не веб-страницы, а заточены для поиска определённых типов файлов: картинок, видео, PDF, mp3 и т.п.. Или поисковики работающие только в определённых портах: торренты, gopher, FTP, whois и т.д.. Но, если всё таки, обратится к национальным веб-поисковикам, то это совсем не значит, что экспериментальные слова на русском, в теге marquee, невозможно отыскать. Если Kaz.kz, казахская система, а Казахстан одна из бывших республик Советского Союза, входит в состав единого таможенного пространства с Россией, тесно с ней связана, и русский в Казахстане второй государственный язык, то конечно удивляться не приходиться, что Kaz прекрасно индексирует русскоязычные сайты. А вот посмотрим чешскую машину поиска Seznam.cz, первоначально она дала отрицательный ответ:

Правильно, это поиск по чешским сайтам, теперь переключимся на поиск по Всемирной сети и странные даже для русских людей, слова были найдены, впрочем и Яндекс, то же считается национальной русской системой, но ищет, по всему Интернету:

Продвинемся вглубь Европы, попробуем германский поисковик, далеко не первый по рейтингу в Германии, FireBall.de. Сам сайт Огненного Шара создан на Ajax:
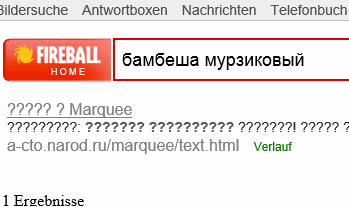
Несмотря на проблему с кодировкой, при выдаче результата, (кириллический текст заменён знаками вопроса), мы видим, что немецкий FireBall, нашёл требуемый пример. Из Германии переместимся в Италию, и потревожим Вергилия, Virgilio.it, кстати, то же, легенду поиска:
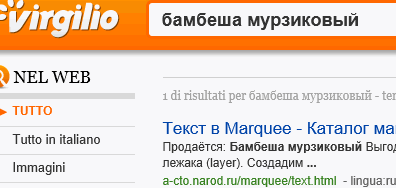
Забудем о том, что средневековый итальянский поэт Данте, в своём бессмертном произведении Божественная комедия выбрал проводником в Ад античного поэта Вергилия (путешествие в Рай Данте не успел создать). Мы видим, что первейший поисковик Италии, Вергилий, обнаружил наши два очень странных слова в бегущей строке, О, белиссимо!!!.
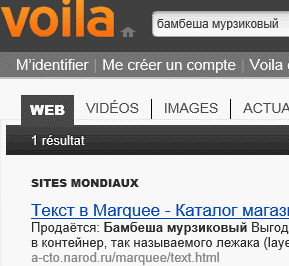
Хорошо справился с задачей французский поисковый портал Voila;
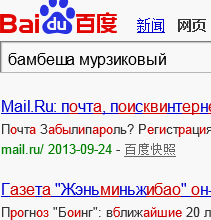
Резко перейдём в Азию, китайская система Baidu не обнаружила искомую пару слов, но взглянув на результаты поиска, можно понять, что русскоязычный поиск это не её конёк, ну и не стоит удивляться, система заточена под китайский язык, под иероглифы, а то что Байду пятая по посещаемости система в мире объясняется, тем, что китайцы самый многочисленный народ в мире, а значит самый большой контингент пользователей Интернета.
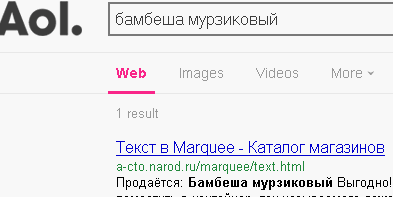
Закончить обзор поисковиков, автор решил запросом зверушку в открытом каталоге Мозиллы DMOZ, заранее зная, что ответ будет отрицательным:

Дело в том что, DMOZ это белый каталог (совместный проект AOL, Alexa, Mozilla). Самый авторитетный белый каталог Интернета. В базах данных каталогов, хранятся не копии документов, а только ссылки на сайты, иногда с кратким описанием ресурса. В DMOZ, ссылки создаются группой модераторов, которые внимательно изучают каждый сайт, и требования к ресурсу, очень жёсткие. Поэтому наличие ссылки в этом каталоге значительно повышает рейтинг сайта, особенно в Google Rank. А-СТО подавал заявку на регистрацию в DMOZ, но получил отказ. Есть ли в DMOZ, народные сайты, да есть. Почему, автор указал на этот ресурс? Да, потому, что в списках поисковых машин DMOZ, встречается очень часто, хотя таковой не является. Включение Дмоза в списки поисковиков, наверное связано с тем, что у многих поисковых систем, имеются каталоги, например у Яндекса. А, поисковик Yahoo!, первоначально вообще, был создан именно, как каталог ссылок, а уже потом стал поисковой машиной. Ну, а если у читателя возникнет вопрос, а как собственно индексирует AOL нашего зверька, проверяем и убеждаемся АОЛ находит странные слова.
в начало страницы
Апокриф веб-дизайна Ускорение и замедление в Marquee Текст в Marquee Графика в Marquee Формы в Marquee Скорость Marquee Поведение Marquee
